advanced java (八) java 集合类
advanced java (八) java 集合类

集合框架是 java 最重要的支柱之一,它是支持 Java 语言语言的基本概念。
java集合类主要分为两种类型,一种是不线程安全的,在 java.util 里面实现 Collection 接口 ;一种是线程安全的 ,在 java.util.concurrent 里面,同样实现 Collection 接口 。
主要来说Collection 分为三大类。
一个是实现 List 接口的, 链表就是线性表的链式存储结构 。 有 ArrayLsit ,储存在一个数组里面的单向链表。有 LinkedList ,一个具有双向链表的链表。继承 Vector 的 Stack ,一个限定仅在表尾进行插入和删除操作的栈实现。
一个是实现 Queue 接口的, 队列就是一个先入先出(FIFO)的数据结构 。有 PriorityQueue,总是获取权值最小的元素,带优先级的队列。有 Deque ,双向队列的实现。 有 ArrayBlockingQueue 和 LinkedBlockingQueue ,都是有界队列。有 DelayQueue ,用于时间调度。有 SynchronousQueue ,简单聚集(rendezvous)机制。
一个是 Set 接口,不包含重复元素,无序的元素的集合 。 有 HashSet ,无序并用hash保证不重复。有 TreeSet ,可用来内部元素排序,是有序的。
Map 储存key-value 结构,可以通过键来获取值。
有 HashMap 这种线程不安全的结构。同样也有线程安全的 HashTable 和 ConcurrentHashMap 。有 TreeMap ,是一种有序的key-value 结构实现。 WeakHashMap ,弱引用的实现。
最后再说一下跳表结构 SkipList , 以及对应的实现,一种不稳定的数据结构,一般用于并发算法。
Collection 的三种类型接口 和 Map 接口都有用于枚举类型的实现,一般以 Enum 前缀表示。以及 Navigable
前缀表示可以获取临近的两个元素,也就是说是排序 (Sorted 前缀)的继承接口。
List
ArrayList
ArrayList 是实现List接口的动态数组,所谓动态就是它的大小是可变的。实现了添加、删除、修改、遍历等功能。
当然 ArrayList 是线程不安全的,涉及到并发时,使用CopyOnWriteArrayList。
ArrayList 的默认容量(capacity)大小是 10,也可以在初始化的时候设置。当由于增加数据导致容量不足时,新的容量 = ( 原始容量 x 3 ) / 2 + 1 。每次扩容相当于将全部元素克隆到一个新数组中。
实现一个 RandomAccess 的标志接口,表示支持快速随机访问。 通过索引值去随机访问元素,复杂度是 O(1)。
同样也可以使用迭代器 iterator 遍历。
LinkedList
LinkedList 相比 ArrayList,是通过节点 ( Node<E> ) 的形式储存链表。
LinkedList同时继承了AbstractSequentialList类和实现了Deque接口,可以克隆和序列化。
因为LinkedList实际上是通过双向链表去实现的,所以它的顺序访问会非常高效,而随机访问效率比较低。
当使用get方法时,索引值会先和长度的1/2比较,选择从末尾还是开始查找。
LinkedList可以作为先进先出(FIFO)的队列
| 执行动作 | 队列方法 | 说明 |
|---|---|---|
| add(e) | addLast(e) | FIFO队列末尾添加一个元素 |
| offer(e) | offerLast(e) | FIFO队列末尾添加一个元素,有返回值 true |
| remove() | removeFirst() | 去掉一个FIFO队列首端元素 |
| poll() | pollFirst() | 取出FIFO队列首端的元素 |
| element() | getFirst() | 获取FIFO队列首端元素的值,但是不取出元素,null会抛出异常 |
| peek() | peekFirst() | 获取FIFO队列首端元素的值,但是不取出元素 |
可以作为后进先出(LIFO)的栈(stack)
| 执行动作 | 队列方法 | 说明 |
|---|---|---|
| push(e) | addFirst(e) | 栈顶添加一个元素 |
| pop() | removeFirst() | 栈顶去掉一个元素 |
| peek() | peekFirst() | 获取栈顶元素的值,但是不取出元素 |
Stack 和 Vector
Stack继承Vector ,就目前来说 不推荐使用 Stack 和 Vector,应当用LinkedList来实现对应功能。
Vector 是由数组实现的集合类,而且还有一些synchronized 修饰的同步方法,默认扩展又是2倍。这样的组合对性能实在是有很大影响。
Stack既然只是push、pop 等操作,那么就不应该复用 Vector 的方法,设计上不严谨。
Queue
PriorityQueue
PriorityQueue是一种优先队列,保证每次取出的元素都是队列中权值最小的。
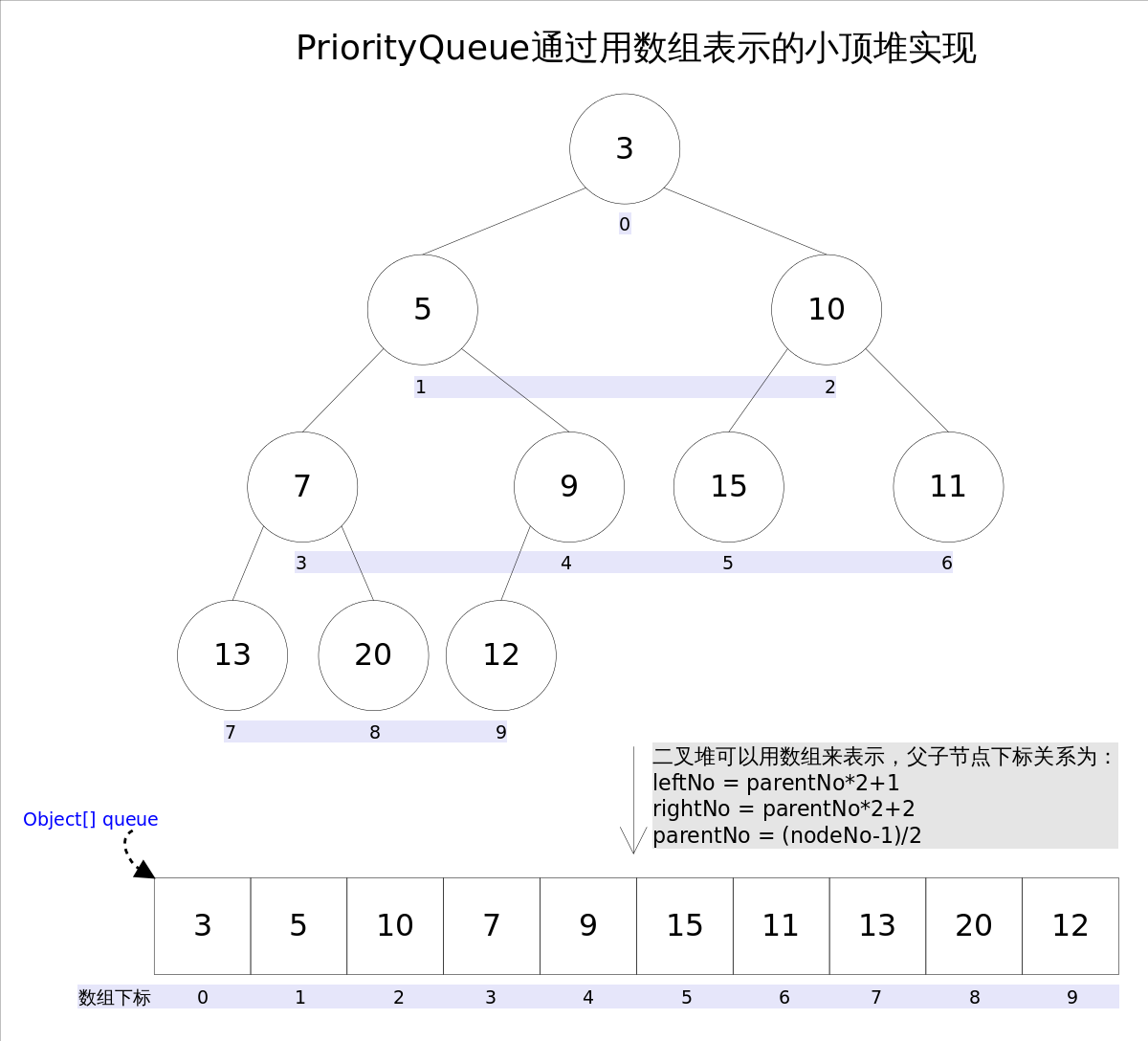
通过完全二叉树(complete binary tree)实现的小顶堆,而通过一个数组储存这个二叉树,遍历方式是层序遍历。每次扩容1.5倍,然后拷贝到新的数组。不允许插入 null 。
而每次插入新的数据时,就是和父节点比较,如果比父节点小,就调换顺序。这样保证了根节点是最小的。最坏情况的复杂度是 O(log n) 。
如果比较对象,要实现 Comparable 接口。
ArrayBlockingQueue
ArrayBlockingQueue是一个阻塞队列,使用数组储存数据,初始化的时候需要指定队列大小。
当队列满的时候,使用 add 插入数据会抛出 IllegalStateException: Queue full 的异常,使用 put 会一直阻塞,直到有其他线程取出数据,offer 会返回特殊值。
当队列里没有数据的时候,使用 remove 取出数据会抛出 NoSuchElementException 的异常,使用 take 会一直阻塞,直到有其他线程插入数据,poll 会返回特殊值。
同样没有数据的时候,不取出只检查元素,使用 element 同样会抛出 NoSuchElementException 的异常,peek 会返回特殊值。
LinkedBlockingDeque
LinkedBlockingDeque 是 Deque 接口的一个实现,是一个双向阻塞队列,通过节点 ( Node<E> ) 的形式储存数据,初始化如果没有指定容量,容量将是Integer.MAX_VALUE。
LinkedBlockingDeque 和ArrayBlockingQueue一样可以在多线程下使用。LinkedBlockingDeque 使用一把锁和两个条件( notEmpty 和 notFull )来保证线程安全。
Set
HashSet
HashSet 实际上是 HashMap 的实现,key 储存值,value 保存一个私有静态不可变对象 PRESENT。
TreeSet
TreeSet是依赖于TreeMap的NavigableSet接口的实现,实际上是个TreeMap的实例。
Map
HashMap
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
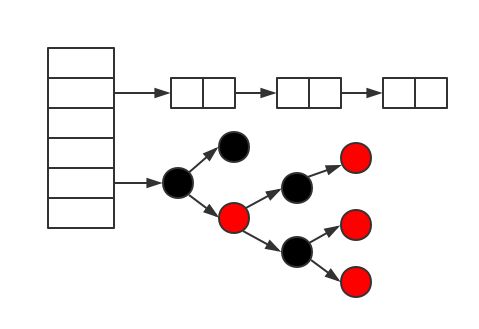
HashMap 使用 Map.Entry<K,V> 储存数据,除了key和 value,还有一个 int 的 hash 字段,以及 next 字段。
数组
如果初始化没有指定数组长度, Node[] table的初始化长度默认值是16。
负载因子表示散列表的密集程度,越大能保存的键值对越多, float loadFactor 的默认值是0.75,这个值可以大于1。
int threshold 表示允许的最大元素数目,超过这个数字将会触发扩容(resize),公式为
threshold = initialCapacity * loadFactor
hashCode
通过公式 (h = key.hashCode()) ^ (h >>> 16) 计算出 hashCode 。
相比于 java7 的算法 h & (length-1) ,因为 length 一般不大,只有低位参与了异或,而 java8 的这种算法高位也参与了异或,会使 hash 值更加散列,同时性能也更好。
扩容
当插入新的键值对时,先判断 table[i] 是否为空或为null,不然就扩容。
然后再判断链表长度是否大于8,小于就加入链表(如果 key 已存在就替换),大于就转化为红黑树。当然删除元素的时候,如果小于6,红黑树会退化成链表。
插入成功后,再和最大元素数目 threshold 做比较,判断是否扩容。
每次扩容是2倍扩容,使用一个新的数组代替已有的容量小的数组。
相比于 java7 同样做了一些优化。相比与之前需要重新计算 hash,而在 java8 里面采用了新的 hash 算法,可以发现,当扩容后,只需要新增的那个最高位bit是1还是0就好了,是1 就 原索引 + oldCap 就可以了。避免了重新计算hash,而且这种做法从概率上讲,分配是平均的。
红黑树
红黑树将链表的复杂度从 O(n) 降低到了 O(log n) ,也是 java8 的一个优化。

红黑树是一个有序二叉树(ordered binary tree),有序二叉树具有以下性质
- 左子树上所有结点的值均小于它的根结点的值
- 右子树上所有结点的值均大于它的根结点的值
- 任意节点的左、右子树也分别为二叉查找树
- 没有键值相等的节点
而红黑树保证了到达到底叶节点的复杂度的相对平衡,使用着色的方法来保证,具有如下性质
- 每个结点要么是红的要么是黑的
- 根结点是黑色的(包括 NIL 节点)
- 叶子节点都是黑色的
- 如果一个父结点是红的,那么它的两个儿子都是黑的
- 对于每个叶节点,路径都包含相同数目的黑结点
二叉树在插入和删除节点后,需要保证上面的性质,所以有 左旋 和 右旋 操作来保证。通过旋转的目的是改变两棵子树的高度,并且任然保持二叉搜索树的性质。
HashTable 和 ConcurrentHashMap
HashTable是 不推荐使用 的,如果遇到多线程的情况,使用 ConcurrentHashMap。
但是还是在这里比较一下 HashTable 和 HashMap 的区别
- HashMap允许 key 和 value 是 null,HashTable不允许
- Hashtable 的 contains 容易误解,HashMap使用的 containsValue 和 containsKey
- HashTable使用Enumeration,HashMap使用 Iterator
- Hashtable 数组默认大小是 11,扩容是 old * 2 + 1,HashMap 默认大小是 16,扩容是 2 的指数
- hash值不同 Hashtable 直接用的 hashcode
由于 Hashtable 使用的是 synchronized 保持一个整体的同步,性能较差。一般会用 ConcurrentHashMap ,ConcurrentHashMap 在 java7 中最重要的就是使用了分段锁(Segment)。
Segment 继承自 ReentrantLock ,在默认并发级别会创建包含 16 个 Segment 对象的数组。
- 用分离锁实现多个线程间的并发写操作
- 将 HashEntery 的key,hash,next 都声明为 final 型,在访问某个节点时,这个节点之后的链接不会被改变。这样可以降低读操作对加锁的需求
- 用 Volatile 变量协调读写线程间的内存可见性
在 java8 中放弃了 Segment 方案, 直接使用一个大的数组。这是因为使用新的hash方案,每个没有hash碰撞的 bucket 可以单独地更新,如果没有头结点,用CAS进行添加;如果有头结点,在更新的时候通过 synchronized 用链表的头节点做为锁。
WeakHashMap
在这种Map中,key的类型是 WeakReference 。如果对应的key被回收,则这个key指向的对象会被从Map容器中移除。
WeakHashMap 一般用于这种场景。我们需要保存一批大的图片对象,其中 values 是图片的内容,key是图片的名字,将 图片的名字置成 null ,就能将图片 GC 回收。
WeakHashMap<AtomicReference<String>,String> weakHashMap = new WeakHashMap<>();
AtomicReference<String> imageName = new AtomicReference("MonaLisa");
String content = "content";
weakHashMap.put(imageName,content);
imageName = null;
System.out.println(weakHashMap); //{MonaLisa=content}
System.gc();
System.out.println(weakHashMap); //{}
TreeMap
TreeMap实现了NavigableMap接口,而NavigableMap接口继承自SortedMap接口,具有了和相邻两个元素比较的能力,也就是说,能比较元素大小。
实现SortedMap接口,TreeMap中的元素可以返回头尾元素,和排序后某两个元素之间的元素。
实现NavigableMap接口,TreeMap中的元素可以获取临近的元素,也可以操作临近的元素。
TreeMap的元素必须要实现Comparable接口,不然会抛出java.lang.ClassCastException 的异常。
TreeMap 的底层是通过红黑树来实现排序的。在访问下一个元素的时候,如果有右子树的节点,也就是去寻找右子树的最左节点;如果没有有右子树的节点,就是左子树的第一祖先节点(中序遍历)。
SkipList
跳表是一个不稳定的数据结构,一般用于并发,有实现 ConcurrentSkipListMap , ConcurrentSkipListSet 实质上是一个存 key 值的 ConcurrentSkipListMap。
跳表一般用来对数据进行高效的查找,插入和删除数据操作也比较简单,最重要的就是实现比较平衡二叉树(红黑树,AVL树)真是轻量几个数量级。缺点就是存在一定数据冗余。
最坏的复杂度同样是 O(log n)
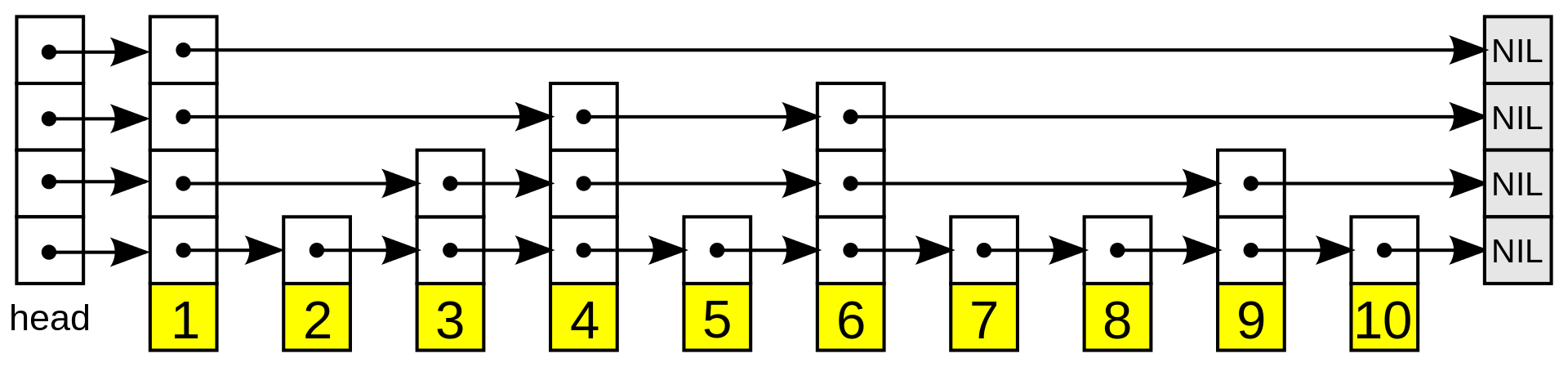
提升节点是通过 1/2 、1/2 的 1/2 … 的几率随机决定的,所以不稳定,本质上是使用空间换时间。
由于插入、删除可以在跳跃列表不同的部分并行地进行,而不用对数据结构进行全局的重新平衡,因此并发性能好。
如果需要一个更快的顺序遍历,并能忍受额外的插入开销,使用ConcurrentSkipListMap。如果不需要并发,使用TreeMap。
