advanced java (七) Linux IO复用
advanced java (七) Linux IO复用
web开发在目前占到了很大一部分市场。而web一个绕不开的话题就是网络的IO复用。
首先我们需要了解CPU是如何收到网络消息的。一般来说,网卡把数据写入到内存,CPU会 中断 正在执行的程序,操作系统便能得知有新数据到来,再通过网卡中断程序去处理数据。
而我们知道对于这种中断操作, 用户态 的程序是没有权限的。这是一种保护模式,防止进程随意使用一些操作系统的特权。而硬件,如网卡的中断信号,也就是会去通知进程。
这个时候,就会涉及到 用户态 到 内核态 的 转换 ,这也就是 select/poll/epoll 模型关注并需要处理的问题。在 内核态 时,也就是CPU进入更高特权级(privilege)的工作模式。特权级别的转换一般是 RING3 -> RING0,数字越低级别越高,RING保证了系统稳定运行。
这里一般来说会涉及到两次转换过程,即 用户态到内核态的转换,然后内核态到用户态的转换,转换之后就是处理数据。
在这里首先会说明五种常见的IO模型,分别是 阻塞io ,非阻塞io ,io复用,信号驱动io,异步io。
对于IO模型,处理方式也分为两种,即反应器模式 (Reactor) 与前摄器模式(Proactor),两者的主要区别是一个是去分发事件,通知别人去读取,而另一个是主动完成事件,然后交给别人处理。
而 select ,poll,epoll 都是Linux IO 复用的不同处理方式,分别会用三种方式的伪码去解释其中的原理,而且解释后者解决了前者什么痛点。select -> poll -> epoll 的发展模式,目前大多数情况下,如 nginx,都是使用的 epoll,少数情况会使用前面两种方式。
同样使用以上 IO 复用方式都解决了多线程的问题,一般由几个线程,每个线程会处理多个事件,节省计算机资源。我们知道 linux 里面一切都是文件,这里就要引入一个重要的概念 、文件描述符(file descriptor),一般使用缩写 fd ,描述符用来指定待读写事件。需要注意的是多个事件来的时候,fd 不是顺序的,比如编号可能会是 1、4、6、22、99…
最后会说一下 epoll 的边缘触发与水平触发的问题。
IO模型
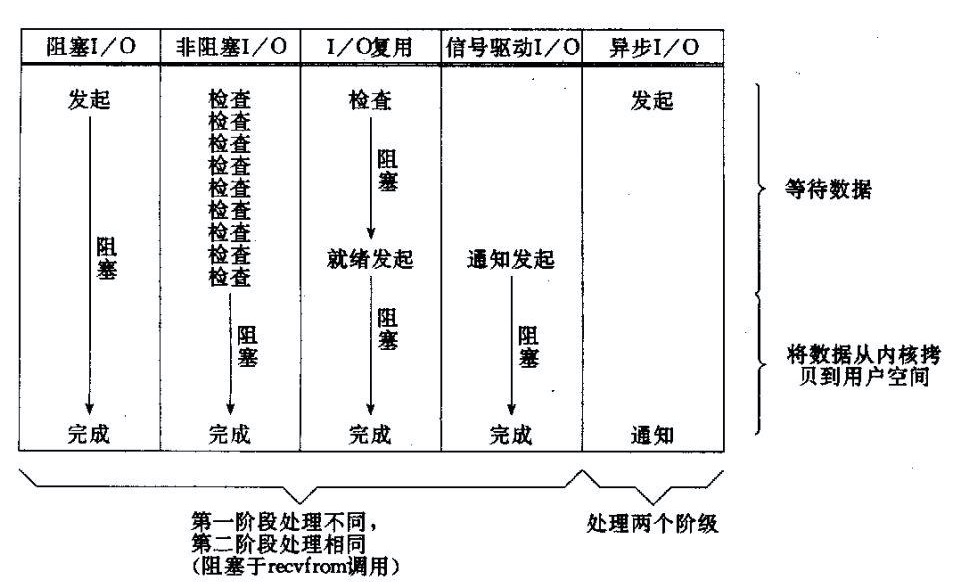
阻塞IO
对于同步阻塞 IO ,即在调用系统的 recvfrom 调用之后,进入内核态,线程阻塞。知道系统内核接收到数据并把数据拷贝到用户空间 buffer 全部完成后,才能从阻塞中恢复。
这个线程在没有读/写过程中接受数据的时候,会一直阻塞在当前代码行,也就是说,每个Socket套接字就需要使用一个线程来处理。也就是说,当大量网络请求的时候,会启动大量的线程,造成很大的开销。
非阻塞IO
非阻塞IO阻塞IO的基础上,如果一个连接不能读写(socket.read() 或者 socket.write(),返回 EWOULDBLOCK 错误,或者说返回0),这样线程就是非阻塞的了,在当前代码行不阻塞,这样我们可以使用一个循环去调用,直到有数据,跳出循环。这也是为了能够复用IO做准备。
IO复用
select/poll/epoll 模型采用的就是这种模式。
相比之前,我们可以将多个IO,以列表的形式在一个线程内对所有的 IO 进行轮询,轮询完所有IO后,只要存在一个返回结果,就跳出循环,将列表的所有返回结果的IO在轮询后处理。
我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写,这样就可以启用少量线程来处理大量网络请求。
这里的非阻塞IO复用采用的是基于事件驱动思想,也就是Reactor模式。
信号驱动IO
信号驱动的 IO 并不需要用户程序去查询是否有 IO 数据到达,而是让用户程序在系统中注册。当数据到达时,内核反过来通知用户程序,用户程序阻塞并开始进行 buffer 拷贝。
也就是说在轮询的时候就做了更多的处理,就已经将数据从内核拷贝到了内核空间,因此这个阶段也就不需要阻塞地去轮询了,因为它关注的是完成事件。而后,通知处理器去处理这些事件就可以了。当然这也是为能够异步IO做准备。
异步IO
通过信号驱动IO,可以将通知处理器的步骤放在了第一阶段,那么处理器就可以直接发起一个异步读写操作,这个时候通知到注册的程序就可以异步地处理了,这也是和同步的非阻塞IO之间的区别。
这种被称作Proactor模式。
遗憾的是,Linux 尚未实现真正异步的网络 IO 。实际情况下,程序需要阻塞在拷贝 buffer 过程。Windows 、Solaris 等系统的 IOCP 模型倒是能够异步。
Reactor与Proactor
IO多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自事件源的I/O事件分离出来,并分发到对应的read/write事件处理器(Event Handler)。
当然,无论是同步的Reactor,还是异步的 Proactor,还可能有一个回调处理器( Completion Handler ),在处理器处理完后,再通知回去。
以IO读操作举例
Reactor
- 等待事件到来(Reactor负责)。
- 将读就绪事件分发给用户定义的处理器(Reactor负责)。
- 读数据(用户处理器负责)。
- 处理数据(用户处理器负责)。
Proactor
- 等待事件到来(Proactor负责)。
- 得到读就绪事件,执行读数据(现在由Proactor负责)。
- 将读完成事件分发给用户处理器(Proactor负责)。
- 处理数据(用户处理器负责)。
因为Proactor注册了用户处理器,这样读到后就可以去通知,用户处理器不需要等待,就可以去异步地处理了。
Reactor用于同步IO,而Proactor用于异步IO。
IO 复用
select模型
伪代码
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&addr, 0, sizeof (addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd,(struct sockaddr*)&addr ,sizeof(addr));
listen (sockfd, 5);
//这里创建了5个fd,并监听5个连接
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
fds[i] = accept(sockfd,(struct sockaddr*)&client, &addrlen);
if(fds[i] > max)
max = fds[i];
}
//这里也就是去给 bitmap 置位,当网卡有数据接收时,也就是有fd了, 先将bitmap初始化
while(1){
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset); //将bitmap全部重置0
}
puts("round again");
//这里就是select核心函数了
//在这里会有一次 用户态 -> 内核态 的转变 ,这里直接将bitmap 全部拷贝到内核态
//以内核态来判断是否有数据,如果有数据 FD置位,然后不再阻塞
//如果fds有1、6、8 , 那么 bitmap是 01000010100...
//如果没有数据,这里就是阻塞代码行
select(max+1, &rset, NULL, NULL, NULL); //不处理写事件,错误事件,不设置超时时间,使用默认超时时间
// 这里是用户态操作,内核态 -> 用户态
for(i=0;i<5;i++) { //需要遍历完整的列表
if (FD_ISSET(fds[i], &rset)){
memset(buffer,0,MAXBUF);
read(fds[i], buffer, MAXBUF); //读取 FD置位 的 buffer里的数据
puts(buffer); //用户处理器
}
}
}
return 0;
}
在select中存在以下缺点
- bitmap的大小是1024位的,意思是同时只能处理1024个连接
- 两次用户态和内核态的转变,有开销
- 其中将fd加入bitmap涉及一次遍历,读取buffer涉及一次遍历,有两次 O(n)遍历的开销,如果加上重置 bitmap,那么还有一次遍历开销
poll模型
伪代码
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
//这里放弃使用 bitmap ,而是传入一个结构体
struct pollfd {
int fd;
short events; //事件类型 读/写/读+写
short revents; //用这个参数来置位,替代 bitmap
}
for (i=0;i<5;i++)
{
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
pollfds[i].events = POLLIN;
}
sleep(1);
while(1){
puts("round again");
//这里是poll的核心函数,同样是 用户态 -> 内核态 的转变,同样如果没有数据,就会阻塞
//5表示传入5个pollfd,50000超时时间
poll(pollfds, 5, 50000);
//内核态 -> 用户态
for(i=0;i<5;i++) {
if (pollfds[i].revents & POLLIN){
pollfds[i].revents = 0; //重置0
memset(buffer,0,MAXBUF);
read(pollfds[i].fd, buffer, MAXBUF); //读取buffer里的数据
puts(buffer); //用户处理器
}
}
}
解决的问题
- 1024的限制,但是如果超过 1024 个fd后,还是需要拷贝和遍历这么多的fd,性能仍会下降
- 少了一次重置 bitmap的遍历开销
但是其他问题依然没有解决
epoll模型
伪代码
struct epoll_event events[5];
int epfd = epoll_create(10); //这里的10其实没多大意义,只要大于0就行
...
...
for (i=0;i<5;i++)
{
static struct epoll_event ev;
memset(&client, 0, sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);
ev.events = EPOLLIN;
//这里是很重要的函数
//相当于在epfd 里面写入 fd-events 的数据
// epfd 由用户态和内核态共享内存,所以也就没状态改变了
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev);
}
while(1){
puts("round again");
//这里是epoll的核心函数
//这里和之前的置位有些区别了
//这里是将有数据的 fd-events 重排,也就是将有数据的 fd-events 排到最前面
//返回值 nfds 就是表示有数据的 fd-events 有多少个
nfds = epoll_wait(epfd, events, 5, 10000);
for(i=0;i<nfds;i++) {
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF); //读取buffer里的数据
puts(buffer); //用户处理器
}
}
解决的问题
- 由于使用 epfd ,也就没有两次状态转换的开销了
- 使用 nfds ,第二次的遍历开销由 O(n) -> O(1)
当然其中还有一些细节问题
其中就是拷贝的问题,假如存在10000个有数据的fd,那么之前还是需要拷贝这么多数据。事实上这个集合变化并不频繁,不需要每次都构建一个完整的集合。应该用增加,删除操作来处理。设立几个操作:EPOLL_CTL_ADD EPOLL_CTL_MOD EPOLL_CTL_DEL 。这样,我们在拷贝上的开销就减少到了最低。
在这里 linux 对 epfd 的处理就是使用了一个 红黑树 ,所以 epoll_create 初始容量的参数就没有意义了。当然,这里是历史遗留问题,因为 Linux 2.6.8 之前使用的是 hash。epfd 中有数据的 fd-events集合,也叫 ready_list
由于用户空间和内核空间的地址映射到同一块物理内存上,就不用拷贝fd集合了。
而epoll将epoll_ctl,即添加等待队列的过程放在了外面,相比于select每次循环都要有一次添加等待队列的过程,提升了效率。每次不需要添加等待队列,只要执行epoll_wait 阻塞就可以了。
水平触发与边缘触发
epoll提供两种触发机制: level-triggered (LT) 和 edge-triggered (ET) 。
在水平触发情况下,在整个 buffer 的状态(读事件buffer不为空,写事件buffer不满),信号都会持续发出,即满足条件的就触发。只要内核缓冲区中还有未读数据,就会一直返回描述符的就绪状态。
而在边缘触发的情况下,信号仅在 buffer 状态变化时发出,即仅在发生变化时才触发。读操作时,缓冲区数据变多不会去通知,只有由空的buffer变为不空时,才会去发送信号通知(通过修改EPOLLIN)。写操作时,缓冲区数据变少(数据被送走)不会去通知,只有满的buffer刚腾出空间就有写事件时,才会去发送信号通知(通过修改EPOLLOUT)。
边缘触发条件要苛刻些,当然每次 epoll_wait 需要遍历的集合也就少一些。
使用边缘触发
如果在注册到epoll实例时使用了EPOLLET选项(使用边缘触发),epoll_wait 在描述符发生变化时才会返回事件,直到每次read或者write返回EAGAIN时才继续等待下一次事件。
LT 模式下的触发和遍历都要更多一些,看起来性能会更弱一些。不过,在良好网络状况的状态下,buffer一直有数据,两种方式的性能就没多大区别。
而且使用ET还需要考虑避免饥饿的问题。可能要考虑在一次循环中将所有数据全部读取出来,不然之后 epoll_wait 如果没有通知,剩下的数据将无法取出。LT每次都会通知,时效性好一些。ET在一些特定环境下比LT好。
如像 nginx,少一些系统调用(LT相比ET多了开关EPOLLIN 或 EPOLLOUT步骤),对于长期跑满 1G 流量这种,可能会好一些(但是这样buffer其实就一直有数据,还得是那种满足LT而不满足ET的情况,才会让ready_list 变少)。而且大多数情况下,如 redis,微服务,瓶颈在内存、数据库IO上,其实也无所谓。
大多数情况下使用水平触发就可以了 ,LT的鲁棒性还要强一些。
netty 中提供的额外的EpollEventLoop,就采用了边缘触发。

