kubernetes 架构
kubernetes 架构
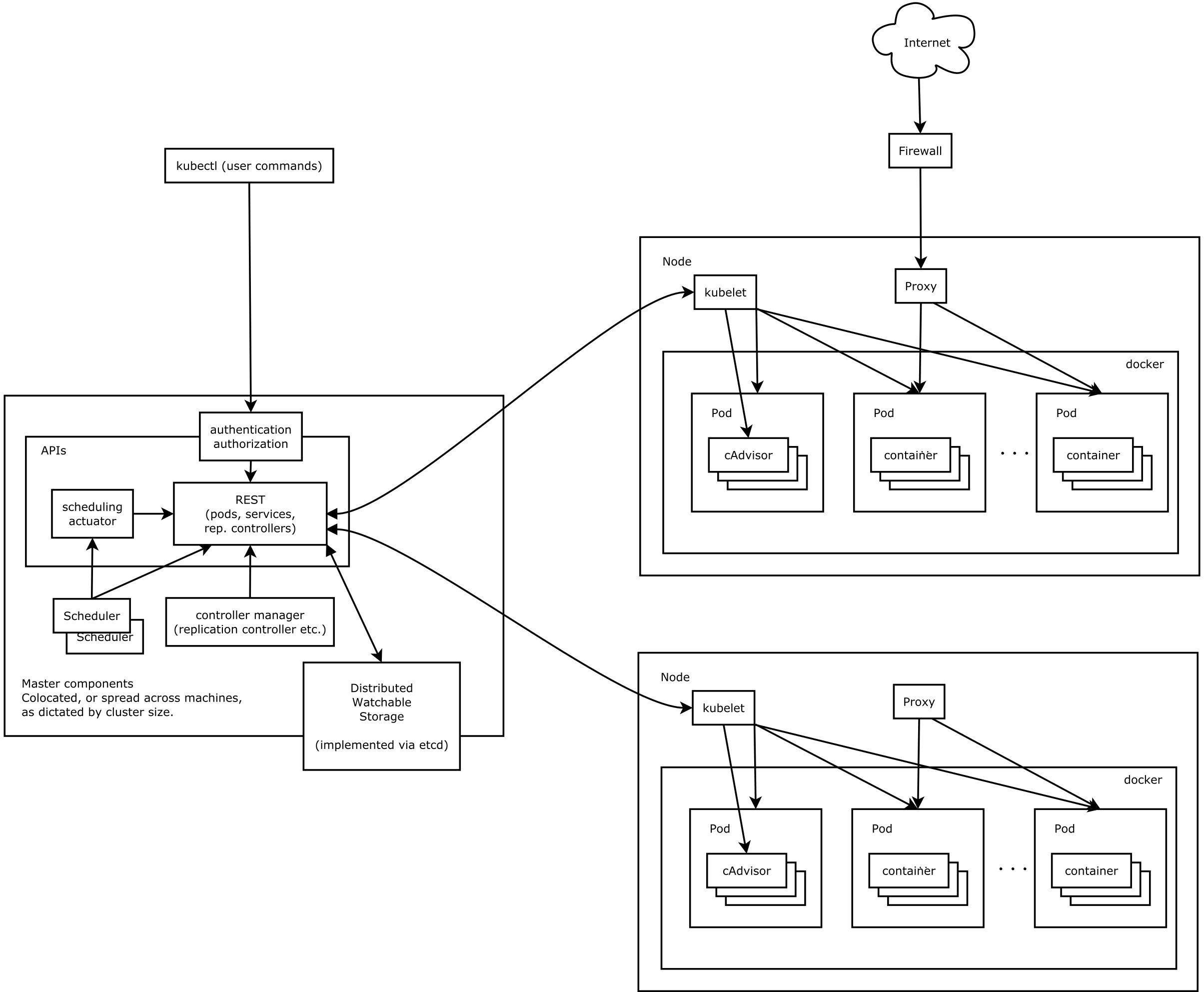
kubernetes 是一个容器集群部署和管理基础平台。起源于谷歌的内部大规模集群管理系统 Borg ,使用 golang 语言实现。
一般来说,主要有以下几个进程通过 systemctl 来管理,分别是 kubelet、kube-apiserver、kube-controller-manager、kube-scheduler 、kube-proxy等关键进程。
- kubelet 是核心进程,负责维护容器的生命周期,同时挂载和网络的管理
- kube-apiserver 是一系列 rest 接口来对资源鉴权、操作,常用的 kubectl 命令行就是调用的这个接口
- kube-controller-manager 是维护 node 集群的状态
- kube-scheduler 是用来通过需求资源来调度部署容器,将 pod 部署到合适的机器上
- kube-proxy 是各节点对内部的服务发现和负载均衡
kube-apiserver
kubectl 或者使用 client-go 程序,实际上是对 kube-apiserver 发送 rest 的 json 或者 Protobuf 请求。然后对 kubernetes API 作对应解析并操作,然后将这些对象储存在 etcd 中。默认端口是6443,存在于 master 节点上。
可以通过修改 /etc/kubernetes/manifests/kube-apiserver.yaml 配置文件,增加以下配置
- --insecure-port=8081
- --insecure-bind-address=0.0.0.0
- --enable-swagger-ui=true
访问宿主机8081端口, 使用 swagger-ui 查看 rest 接口,其中需要安装 Chrome浏览器插件 Allow CORS
可以看出每一个 kubernetes API 资源都有对应的 rest API,和 kubernetes API 对应关系如下
| rest API | kubectl API |
|---|---|
| GET | kubectl get (包括单个对象或列表) |
| POST | kubectl create |
| PUT | kubectl apply (更新) |
| FETCH | kubectl patch |
| DELETE | kubectl delete |
另外,有一些长连接操作,如 cp ,exec ,logs,watch 等。
如 exec,cp 以 websocket 的形式,将请求头设置为 Sec-WebSocket-Protocol v4.channel.k8s.io 和 Upgrade SPDY/3.1
logs 和 watch 是一种 HTTP 长链接 的机制,将请求头设置为 Transfer-Encoding: chunked
kube-controller-manager
kube-controller-manager 的控制器是一个控制循环,它通过 apiserver 监视集群的共享状态,并尝试进行更改以将当前状态转为所需状态。
kube-scheduler
说到 scheduler ,不得不先说 kubernetes 的基本单位 pod。
pod 就像本意豆荚,表示一个 pod 里面可能存在一个至多个 docker 容器。docker 是一种特殊的进程,在 linux 里面是伪隔离,使用的仍然是宿主机的操作系统内核,并不像虚拟机虚拟出一个内核。有自己独立挂载的磁盘空间( rootfs ,比如 /bin,/etc,/proc 等),通过 cgroups 限制内存和cpu资源。
实际上当我们使用 kubectl 对 kubernetes API 对象做操作时,也就是对 kube-apiserver 发送 rest 请求,这个请求的数据压缩格式可以是 json,也可以是 Protobuf 。然后是 kube-scheduler 做对应处理。通过不同的字段,可以水平扩展,也可以滚动更新。
在调度的时候,需要注意对 资源边界 的处理,同时以 Guaranteed > Burstable > BestEffort 的级别设置了调度优先级别。
调度过程如下
- 从 etcd 中获取 kubernetes API 对象
- 放入一个控制循环 (Informer Path)的先进先出优先级队列( PriorityQueue )里面,Informer 去通知并更新调度器缓存,cache 的目的是提高调度算法的执行效率。(这里的控制循环有点类似于 nodejs 的 eventloop 模型,目的是解耦)
- 队列的数据将进入负责 Pod 调度的主循环(Scheduling Path)。队列出栈,并从 cache 中获取相关信息。进入三个阶段
- Predicates 阶段将分析 node 亲和性,污点,资源,挂载等,判断哪些 node 可用
- Priorities 阶段给可用 node 打分,0到100 ,调度给得分最高的 Node
- Bind 阶段给 pod 加上 nodeName 字段,当然这里乐观地只给 cache 加上了,还没有到 etcd,直到调度成功。
可以通过 Go plugin 机制 扩展调度器。
kubelet
kubelet 的核心工作原理是一个控制循环(SyncLoop),流程如下
-
kubelet 启动时,会设置Listers,包括磁盘,OOM,初始化网络插件,dockershim,PLEG,容器GC
-
由调度器发送的调度信息传递到 node 的 kubelet 上
-
进入 SyncLoop ,这个控制循环由以下事件驱动
- Pod 更新事件
- Pod 生命周期变化
- kubelet 本身设置的执行周期
- 定时的清理事件
-
控制循环同时也维护着很多很多其他的子控制循环,如Node Status Manager、Network Status Manager、PLEG Manager、Volume Manager、Image Manager等
-
kubelet 调用下层容器运行时,通过容器运行时接口(Container Runtime Interface,CRI)的 gRPC 接口来间接执行,docker 对应的也就是 dockershim,包括两部分
- RuntimeService:容器的创建、启动、删除、执行 exec 命令等,对于logs,exec 等长连接使用 Streaming API 实现
- ImageService:镜像的拉取、删除等
RunPodSandbox 将 Pod 这个概念映射到容器运行时层面所需要的字段,比如顺序启动容器等
除了 dockershim,容器运行时还有 rkt,有独立虚拟机内核的 Kata Containers,Go 语言实现内核的 gVisor
kube-proxy
有一种重要的资源 service,service 作为 pod 代理的入口,代替 pod 对外暴露一个固定的 ip 地址。
其中涉及到容器之间的数据交换问题,解决方式是通过 Veth Pair 设备 + 宿主机网桥 。
也就是说,在访问 kubernetes 集群内部同一个 node 节点的 ip 地址时,会先根据路由规则到达 docker0 网桥(docker0 网桥是工作在数据链路层),然后被转发到对应的 Veth Pair 的虚拟设备(成对出现的虚拟网卡,一个在docker0 网桥上,一个是容器的 eth0),最后到达容器。
如果是不同的 node 节点,docker0 网桥要再经过一层 eth0,到另外一个 node 节点的 eth0,再到另外一个 node 节点的 docker0 网桥。宿主机的 eth0 网卡是相通的。或者在不同节点的搭建一个公用网桥,使用覆盖网络(Overlay Network)。
一般来说,kubernetes 的网络插件基本上是基于上面的模型,其中包括插件 Flannel 和 Calico 。其中 Flannel 的 UDP 和 VXLAN 方案采取隧道机制,损耗较大。 Flannel 的 host-gw 和 Calico 采取的三层网络方案。
Flannel UDP
启动一个8285 端口的服务,将不同 node 节点的容器之间的 IP 包封装在一个 UDP 包里,通过这个宿主机的 8285 端口转发到不同的容器。这种方案有严重的性能问题,主要是要经过三次用户态与内核态之间的数据拷贝,已经被废弃了。
Flannel VXLAN
虚拟可扩展局域网(Virtul Extensible LAN)会将IP 包经过 docker0 网桥,再到本机 flannel.1 设备进行处理。在flannel.1 设备中,flanneld 会增加一条路由规则,在数据帧中,目的容器的 ip 地址之前,加上一个目的 VTEP 设备的 MAC 地址。然后封装成一个 UDP 包,再在外层再套上一层,目的主机的 MAC 和 ip 地址。再经过宿主机的 eth0 网卡传输。
Flannel host-gw
将 docker0 网桥替代成 cni0 网桥,也就是网络插件,容器运行时接口(Container Runtime Interface)的实现 ,插件的二进制文件放在 /opt/cni/bin 。
host-gw 模式增加一个路由规则,将每个 Flannel 子网的下一条,设置成了该子网对应的宿主机的 IP 地址。这样就减少了封包和解包带来的性能损耗,提高了性能。
需要注意的是,host-gw 必须要求集群宿主机之间是二层连通的。
Calico
Calico 的核心在于边界网关协议(Border Gateway Protocol,BGP),BGP指在大规模网络中实现节点路由信息共享的一种协议,也就是每个边界网关上都会运行着一个小程序,维护着自己的路由表,并能够对收到的数据进行分析,分配到正确的位置。其可靠性和可扩展性比 Flannel 更好。
Calico 交换路由信息有两种模式
- Node-to-Node Mesh 模式:在少于 100 个节点的集群里使用
- Route Reflector 模式:增加一个中间代理,可以在超大型集群里使用
而如果整个集群存在node 节点 ,在多个子网里,那么就要使用 IPIP 模式。
这里 BGP 不再存在于 docker0 网桥的位置,而在 宿主机 eth0 之后,会在 ip 数据包的 IP Header 之上再包装一层 IP Header 。

