advanced java (四) 并发与共享变量
advanced java (四) 并发与共享变量
大多数情况下,讨论的并发问题,事实上难点都是在讨论并发过程中共享变量的安全问题。即如何在并发过程中,保证多个 worker 的共享变量的原子性的问题。
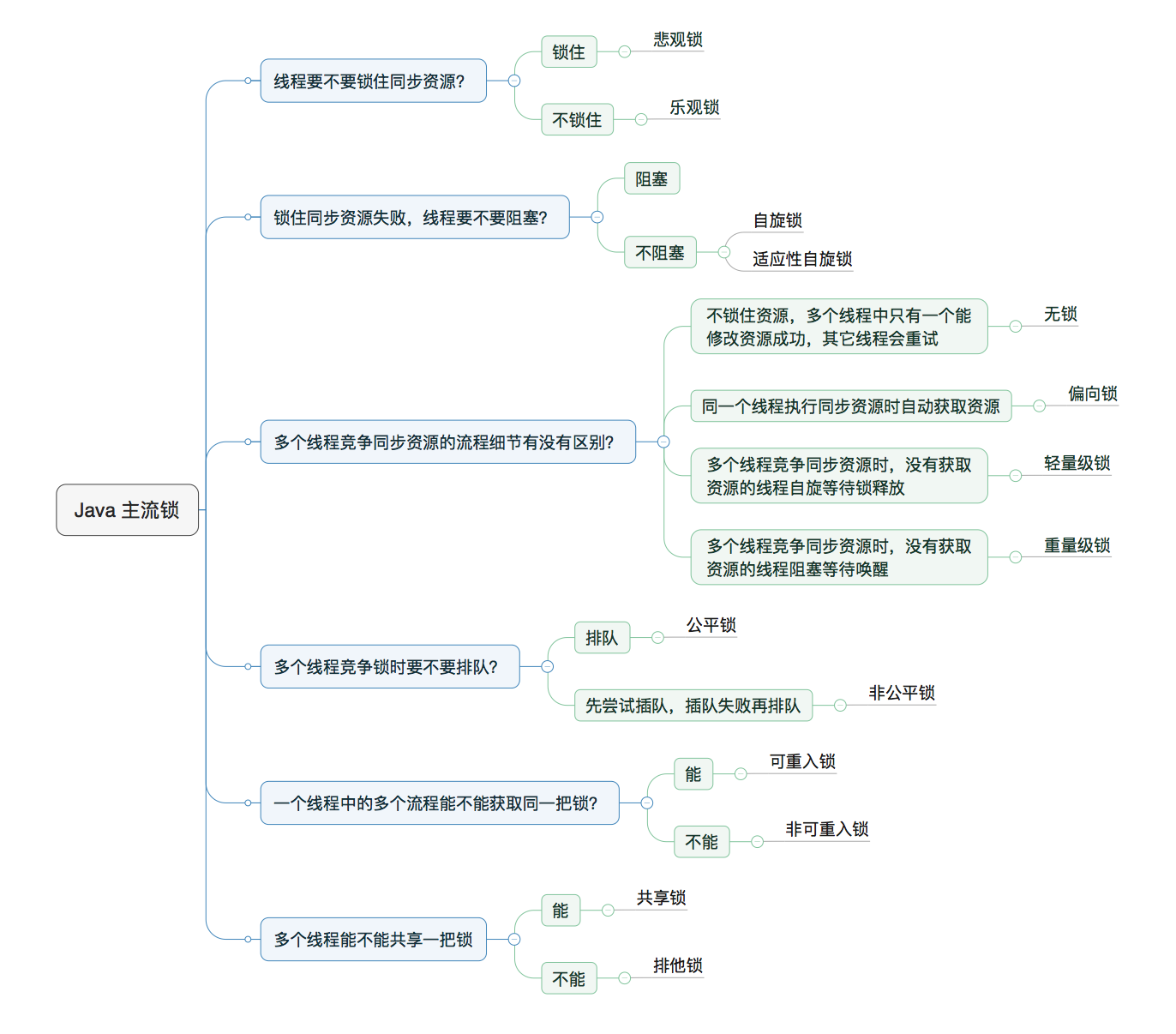
java 中的线程安全是一个不可避免的问题。如何使用锁机制,针对不同的场景,解决读写问题,也可以说是多个线程对同一变量(共享内存)的访问问题。无论是多读少写的 乐观锁 和多写少读的悲观锁。还是阻塞过程中使用 自旋锁 解决多线程竞争的问题。以及 java 中无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁的单向转化问题。跟着是锁的排队问题,即公平锁和非公平锁。而重入锁 (ReentrantLock类 和 synchronized 关键字)避免了死锁的发生。还有的是 读写锁 (ReentrantReadWriteLock类),也就是共享锁和排他锁,java8 提供了乐观的读写锁StampedLock。
而在 java 中的关键字 volatile 保证了变量的可见性和有序性,而互斥量、信号量 也是重要的内容(这个放到java内存模型里面讨论)。JDK也提供了一些栅栏锁类,如 CountDownLatch 、 CyclicBarrier 、 Exchanger、Phaser。
除了锁保证了线程安全,也可以使用函数式并发的技巧。使用流式计算、折叠和 monoid (幺半群,核心思想是结合律),构建一个并发模型。
最后是 CSP 并发模型(communicating sequential processes),核心思想是 不要通过共享内存来通信,应该通过通信来共享内存 。比较 Actor 模型的区别。在有些语言中将这两种模型都置于很重要的地位,正如 golang之于一等公民channel,erlang之于一等公民actor。
Java 锁模型
悲观锁和乐观锁
悲观锁悲观地认为共享变量会经常改变,多用于少读多写的场景。乐观锁乐观地认为共享变量不会被改变,多用于多读少写的场景。
Java中,synchronized关键字和Lock的实现类都是悲观锁。而原子类型,使用无锁编程,采用的是CAS算法自旋,都是乐观锁。
CAS全称 Compare And Swap(比较与交换)。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
CAS 会将需要写入的值和旧值比较,然后去更新这个值,更新会不断重试。
//以AtomicInteger为例,这里是Unsafe类
//AtomicInteger::compareAndSet 实际上是调用的一个Unsafe类的本地方法,只需要知道这个方法是在JNI里是借助于一个CPU指令完成的,是原子性的就可以了
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
//AtomicInteger::getAndSet 就是去不断自旋,判断内存值是否等于新值,直到设置成功退出循环,返回旧值
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var4));
return var5;
}
ABA问题
有可能内存值的变化过程是 A -> B -> A ,CAS就会检查时会发现它的值没有发生变化,就直接更新了,但是实际上却变化了。通过加上版本号解决 1A -> 2B -> 3A。
事实上,或许,Int的CAS并不会有ABA的问题。
但是ABA确实对CAS的定义是有影响的。我们举一个例子,T1线程打算对一个栈 A <- B 的栈顶元素A 做 compareAndSet( A , B ) 时,T2 线程将 A <- B 替换成 A <- C <- D , T1发现还是 A,CAS成功,但是这个时候栈 就是 B 了 ,C、D 入栈失败。
对于对象的CAS操作,java 提供了AtomicStampedReference类,通过一个 对象和时间戳的 Pair 来解决 ABA问题。
自旋问题
自旋和自旋锁差不多,也会有CPU的开销,特别是有多个线程争着改变原子类(多写)时,都会自旋,CPU压力会增大。
自旋锁
阻塞或唤醒一个Java线程需要操作系统切换CPU状态(挂起、恢复)来完成,这种状态转换需要耗费比处理代码长得多的处理器时间。
事实上锁的阻塞时间是很短的,为了稍微等待一段时间,会做for循环的自旋 (默认10 次),但是会增加 CPU的开销。
而java6以后 ,使用的 自适应自旋锁 更加智能,会根据上一个持有该锁的线程的自旋时间以及状态来确定自旋时间。如果刚获得锁,即很有可能可以再拿到锁,加长自旋时间;如果自旋操作很少成功,就减短自旋时间,甚至不去自旋。
Synchronized锁
这里主要讨论的是synchronized 关键字,使用互斥来同步数据,同时也是一个悲观锁。
同步锁一共有4种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
对象头(Object Header)结构
普通对象只有Mark Word 和 Klass Word ,数组对象多了 Array Length
| 长度 | 内容 | 作用 |
|---|---|---|
| 1字宽(32bit) | Mark Word | hashcode、gc分代年龄、锁 |
| 1字宽(32 bit) | Klass Word | 存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例 |
| 1字宽(32 bit,只有数组对象才有) | Array Length | 数组长度 |
对象 Mark Word 的内容
| 锁状态 | 23bit | 2bit | 4bit | 1bit(是否为偏向锁) | 2bit(锁状态) |
|---|---|---|---|---|---|
| GC 标记 | 空 | 空 | 空 | 空 | 11 |
| 无锁 | 对象hashCode(25bit) | hashCode | 对象分代年龄 | 0 | 01 |
| 偏向锁 | 偏向线程的id | Epoch (偏向锁的时间戳) | 对象分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针(30bit) | 指针 | 指针 | 指针 | 00 |
| 重量级锁 | 指向互斥量的指针(30bit) | 指针 | 指针 | 指针 | 10 |
无锁: 要么修改操作在单线程的循环里面进行,要么是CAS原理的应用。
↓ 代码进入同步块
偏向锁:一段同步代码(sync关键字括起来的同步块)一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。偏向锁只需要在置换线程id的时候只依赖一次CAS原子指令(这个线程不再访问,隔了一段时间,另外个线程来访问,但是两者没有争夺锁)。
↓ 一个线程持有锁时,被另外的线程所访问,另外的这个线程会通过自旋的形式尝试获取锁
轻量级锁:其他线程会通过自旋的形式尝试获取锁,即依赖多次CAS原子指令。不会阻塞,但是同时仅有一个线程来尝试获取锁。(乐观地)
↓ 一个线程在持有锁,另外的线程在自旋,又有第三个线程来访
重量级锁:Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。(悲观地)
锁记录(Lock Record),轻量级锁是怎么获得的
当另外一个线程来访问时
首先在当前线程中建立Lock Record(保存在线程中),拷贝并储存对象头Mark Word (保存在对象中,只有一个)
然后将对象头Mark Word 尝试用CAS操作,更新为指向Lock Record的指针,Lock Record (包括 owner指针 和从对象拷贝而来的 Mark Word)里的owner指针指向对象的Mark Word
CAS操作更新 (一次成功就说明自己是另外的线程,失败就说明自己可能是第一个线程或者第三个线程)
成功 / \ 失败
获取轻量级锁成功 \
检查对象头Mark Word是否指向当前线程的栈帧
是 / \ 否
直接进入同步块继续执行 \
Mark Word中存储的变成指向重量级锁(互斥量)的指针
(在 jdk15 中有计划移除偏向锁,原因是偏向锁的维护成本太高,维护偏向锁的代价大于偏向锁对于程序效率的优化 )
锁粗化和锁消除优化
-
锁粗化(Lock Coarsening):将多次连接在一起的加锁、解锁操作合并为一次,将多个连续的锁扩展成一个范围更大的锁,避免在无冲突情况下反复加锁解锁的代价。
-
锁消除(Lock Elimination):锁消除即删除不必要的加锁操作。利用代码逃逸技术,如果判断到一段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁。
公平锁
-
公平锁:多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。效率低 ,但是不会被饿死。
-
非公平锁:多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。缺点就是有的线程真的会等很久,饿死。
在ReentrantLock源码里面可以选择使用公平锁还是非公平锁,默认使用非公平锁
//非公平锁 NonfairSync内部类使用Sync内部类的方法
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
//公平锁 FairSync内部类
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && //只有这里有区别,公平锁如果有队列,就会放入队列,而非公平锁只要CAS成功就插队
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
重入锁
首先,我们思考下产生死锁的4个条件
- 互斥(mutual exclusion):一个资源每次只能被一个进程使用
- 请求保持(hold and wait):一个进程因请求资源而等待时,不会释放已分配的资源
- 不可剥夺(no preemption):进程已获得的资源,在未使用之前,不能被强行剥夺
- 循环等待(circular waiting):若干个进程之间形成头尾相连的循环等待资源的关系
必须要同时满足四个条件,才会发生死锁。而如果是可重入的,即线程可以重复获得它已经持有的锁。这样,在上个流程就能够释放共享变量,即破坏了第二个条件,即使其他三个条件满足,也不会产生死锁了。
ReentrantLock 和 synchronized 的区别
synchronized提供了便捷性的隐式获取锁释放锁机制,而ReentrantLock 提供了获取锁与释放锁的可操作性,可中断、超时获取锁。
AbstractQueuedSynchronizer
AQS即队列同步器,AQS使用一个int类型的成员变量 state 来表示同步状态,当 state>0 时表示已经获取了锁,当 state = 0 时表示释放了锁。它提供了三个方法( getState、setState 、compareAndSetState )来对同步状态 state 进行操作,当然AQS可以确保对 state 的操作是安全的。
而被 tryAcquire 、tryRelease 等方法被 protected 修饰,需要子类有不同的实现,如是否公平。
对于队列里面的线程,用不同的字段表示不用的状态
- SIGNAL(-1) : 正常状态,被阻塞
- CANCELLED(1):因为超时或中断,该线程已经被取消
- CONDITION(-2):表明该线程被处于条件队列,就是因为调用了 >- Condition.await而被阻塞
- PROPAGATE(-3):传播共享锁
- 0代表无状态
AQS通过内置的FIFO同步队列来完成资源获取线程的排队工作,如果当前线程获取同步状态失败(锁)时,AQS则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列(通过 addWaiter 方法,以CAS的形式),同时会阻塞当前线程,当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
AbstractQueuedSynchronizer设计很巧妙,基于阻塞的CLH队列容纳所有的阻塞线程,而对该队列的操作均通过Lock-Free(CAS)操作 , 而且是轻量级锁。
Condition
控制线程释放锁, 然后进行等待其他获取锁的线程发送 signal 信号来进行唤醒
读写锁
独享锁即写锁,共享锁即读锁。
-
如果使用读锁,没有写锁的情况下,那么能够被多个读线程访问。
-
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。在使用读写、写读、写写的时候,会使用写锁,是互斥的。
使用一个32位的volatile int 变量 state,高16位为读锁数量,低16位为写锁数量。
//ReentrantReadWriteLock内部静态类Sync
//写锁尝试
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c); //取写锁的个数
if (c != 0) {
if (w == 0 || current != getExclusiveOwnerThread()) //存在读锁,返回失败
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT) //写锁数量超过2^16,返回失败
throw new Error("Maximum lock count exceeded");
setState(c + acquires);
return true;
}
if (writerShouldBlock() || //如果当且写线程数为0,并且当前线程需要阻塞那么就返回失败
!compareAndSetState(c, c + acquires)) //如果通过CAS增加写线程数失败也返回失败
return false;
setExclusiveOwnerThread(current);
return true;
}
//读锁尝试
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1; // 如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
StampedLock
StampedLock 相比于读写锁,增加了一种乐观获取读锁的实现 tryOptimisticRead。
使用一个非0的stamp版本信息,获取该stamp后在具体操作数据前还需要调用validate验证下该stamp是否已经不可用,也就是看当调用tryOptimisticRead返回stamp后到到当前时间间是否有其他线程持有了写锁(通过CAS操作),如果是那么validate会返回0,否者就可以使用该stamp版本的锁对数据进行操作。
乐观读锁在读线程多写线程少的情况下提供更好的性能。
栅栏类
| 栅栏类 | 机制 |
|---|---|
| CountDownLatch | 当多个线程(count参数)都达到了预期状态或完成预期工作时触发事件,其他线程可以等待这个事件来触发自己后续的工作。 |
| CyclicBarrier | 协同多个进程,让多个线程在这个屏障前等待,直到指定数量(count参数)线程都达到了这个屏障时,再一起继续执行。 |
| Exchanger | 用于两个线程之间的数据交换 |
| Phaser | 多阶段栅栏,可以在初始时设定参与线程数,也可以中途注册/注销参与者,当到达的参与者数量满足栅栏设定的数量后,会进行阶段升级(advance) |
class Process extends Thread{
private Runnable runnable;
private int millis;
public Process(int millis,Runnable runnable) { this.millis = millis;this.runnable = runnable; }
public void run() {
try {
Thread.sleep(millis);
runnable.run();
} catch (InterruptedException e) {}
}
}
CountDownLatch
//当3个栅栏都完成后,await() 执行之后的代码
CountDownLatch latch = new CountDownLatch(3);
Process p1 = new Process(2000,()-> {System.out.println("p1 finished");latch.countDown();});
Process p2 = new Process(2000,()-> {System.out.println("p2 finished");latch.countDown();});
Process p3 = new Process(10000,()-> {System.out.println("p3 finished");latch.countDown();});
Process p4 = new Process(20000,()-> {System.out.println("p4 finished");latch.countDown();});
Process awaitP = new Process(1000,()-> {try { latch.await();System.out.println("await p finished");} catch (InterruptedException e){}});
awaitP.start();
p1.start();
p2.start();
p3.start();
p4.start();
//p2 finished
//p1 finished
//p3 finished
//await p finished
//p4 finished
//当然也可以设置超时时间
Process awaitP = new Process(1000,()-> {try { latch.await(5000, TimeUnit.MILLISECONDS);System.out.println("await p finished");} catch (InterruptedException e){}});
//p1 finished
//p2 finished
//await p finished
//p3 finished
//p4 finished
CyclicBarrier
//当count数量线程都到达barrier后,执行线程后面的代码,同样可以设置超时时间,之后不再叙述
CyclicBarrier barrier = new CyclicBarrier(3);
Process p1 = new Process(2000,()-> {System.out.println("p1 begins to wait");try { barrier.await();System.out.println("p1 finished");} catch (Exception e){}});
Process p2 = new Process(2000,()-> {System.out.println("p2 begins to wait");try { barrier.await();System.out.println("p2 finished");} catch (Exception e){}});
Process p3 = new Process(5000,()-> {System.out.println("p3 begins to wait");try { barrier.await();System.out.println("p3 finished");} catch (Exception e){}});
p1.start();
p2.start();
p3.start();
//p1 begins to wait
//p2 begins to wait
//p3 begins to wait
//p3 finished
//p1 finished
//p2 finished
Exchanger
//用于交换数据
Exchanger<String> exchanger = new Exchanger<>();
Process p1 = new Process(2000,()-> {String s1 = "p1 data";try { exchanger.exchange(s1);System.out.println("get "+ s1 +" , p1 finished"); } catch (InterruptedException e){}});
Process p2 = new Process(5000,()-> {String s2 = "p2 data";try { exchanger.exchange(s2);System.out.println("get "+ s2 +" , p2 finished"); } catch (InterruptedException e){}});
p1.start();
p2.start();
//get p2 data , p2 finished
//get p1 data , p1 finished
Phaser
Phaser phaser = new Phaser();
Process p1 = new Process(0,()-> {
try {
System.out.println("p1 register");
phaser.register();
while (true) {
Thread.sleep(1000);
System.out.println("p1 stage " + phaser.arriveAndAwaitAdvance());
}
} catch (InterruptedException e) {
}
});
Process p2 = new Process(0,()-> {
try {
System.out.println("p2 register");
phaser.register();
while (true) {
Thread.sleep(2000);
System.out.println("p2 stage " + phaser.arriveAndAwaitAdvance());
}
} catch (InterruptedException e) {
}
});
Process p3 = new Process(0,()-> {
try {
System.out.println("p3 register");
phaser.register();
while (true) {
Thread.sleep(5000);
System.out.println("p3 stage " + phaser.arriveAndAwaitAdvance());
}
} catch (InterruptedException e) {
}
});
p1.start();
p2.start();
p3.start();
//p1 register
//p2 register
//p3 register
//p3 stage 1
//p2 stage 1
//p1 stage 1
//p3 stage 2
//p2 stage 2
//p1 stage 2
//...
Phaser 可以完成多阶段栅栏,同时通过注册/注销 可以改变指定到数量。
Phaser 使用一个多叉树型结构来解决大量线程注册的问题,提高并发性和程序执行效率。
Treiber Stack
使用无锁栈(Treiber Stack),保存在Phaser树的根结点中,其余所有Phaser子结点共享这两个栈。Treiber Stack 即在栈顶执行 pop 和 push 时使用 CAS算法,即之前ABA问题举的例子实现,是 lock-free 思想的一种体现。
函数式并发
monoid
什么是 monoid (幺半群)?满足结合律(associativity)和同一律 (identity) ,即需要满足下面三个条件
- 封闭性:所有集合内的元素经过二元运算得到的结果仍然在这个集合内。即,任意两个整数相加的结果仍为整数。
- 结合律:加法结合律
( a + b ) + c = a + ( b + c )。 - 单位元 / 幺元:存在一个元素与任意元素运算结果仍为那个元素。即,0 加任何整数结果都为那个整数。
即 group(群)排除逆元(任意元素都有相反数)条件。如果没有幺元,就被称作 semigroup(半群)。
满足上面的条件,就可以并行化地执行程序,并保证结果一定是正确的。
以加法为例
//使用 parallelStream 并发执行
int[] sum = new int[]{0};
Stream.iterate(1, t-> t +1).limit(100) //1~100 累加
.parallel() //并行执行,即多线程执行
.forEach(num -> sum[0] += num);
System.out.println(sum[0]); //大概率不是5050,因为加法不是原子性的
//单线程执行
int sum2 = Stream.iterate(1, t-> t +1).limit(100)
.reduce(0,(a,b)-> a+b); //单线程执行
System.out.println(sum2); //5050,没错,因为是单线程执行,结果一定是5050
//并发执行,需要注意这里加法是满足结合律的,在累加里面,0即幺元 a + 0 = a , 0 + a = a
int sum3 = Stream.iterate(1, t-> t +1).limit(100)
.parallel()
.reduce(0,(a,b)-> a+b);
System.out.println(sum3); //一定是5050,这里便是 monoid 的并发应用
如果理解了 monoid 我们可以发现有很多满足结合律的计算都可以通过并行执行。
举例来说
累乘
一个列表字符串的顺序concat
count()统计一组数据的数量
求一组数据的最小公倍数,或者最大公约数
求一组数据的最小值或最大值
将一组数据放入不可重复的Set里面
排序 sorted()
Integer max = Arrays.asList(new Integer[]{32,23,66,12,68,11,22})
.parallelStream()
.max(Integer::compare) //这里返回的是Optional<Integer>
.get();
System.out.println(max); //68
这里的幺元是 Optional.of(null),也被称作None。
构建 monoid
假设我们需要在一个很长的段落中统计 the出现的次数。
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way—in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only。
在使用折叠,拆分块(chunk)的时候,或许会丢失掉一些 the 的统计
(It was t)(he best of times, it w)(as the worst of times, it was th)(e age of wisdom, it was t)(he age of foolishness…)
或许需要考虑一些边界情况,将边界上的 the 做一些处理,在拆分文本的时候,如果遇到 the ,不将 the 拆分就可以了。
(It was )(the best of times, it w)(as the worst of times, it was the)( age of wisdom, it was )(the age of foolishness…)
这样就构建了一个 monoid ,可以并行计算了。
组合 monoid
假如 A和B都是monoid,那么 tuple(元组)类型 (A ,B)也是 monoid。
CSP并发模型
与共享数据方式相比,消息传递机制的最大优点就是不会产生竞争。 Channel 和 Actor 即实现消息传递的两种常见形式。
Actor
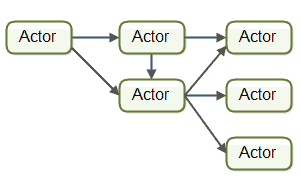
Actor 是由状态(State)、行为(Behavior)和邮箱(MailBox,可以认为是一个消息队列)三部分组成。
Actor彼此之间直接发送消息,不需要经过什么中介,消息是 异步发送 和处理的。因此Actor可以决定自己需要向哪个Actor的邮箱发送数据,是完全解耦的。Actor中有明确的send/receive的关系。同时也是 不阻塞 的。
一个 Actor 可以响应消息:推出新Actor,改变其内部状态,或将消息发送到一个或多个其他参与者。
Actor可能会堵塞自己,但Actor不应该堵塞它运行的线程。
Channel
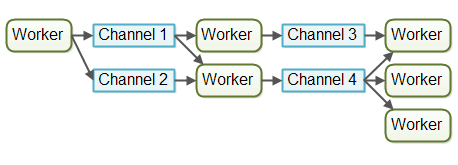
不要通过共享内存来通信,应该通过通信来共享内存(很重要,复读一次)
Channel模型中,有两种类型组成,Worker负责处理数据,而 Channel 保存数据。Channel 是一个先进先出队列,有有缓冲和无缓冲两种类型,即可以限定Channel 的队列长度,或者不限制。
Channel 本身是没有状态的,是由Worker 决定自己去 send/receive 哪个Channel ,通讯耦合度更松。对于有缓冲Channel ,队列是无限长的,而无缓冲Channel。可以通过,设置capacity 设定队列长度。同时也是 阻塞 的。对于数据,由于是先进先出,消息处理是 同步 的。
对于接收方,一般来说处理掉接受的数据,才能去 Channel 获取新的数据,如果自己阻塞了,那么将无法处理Channel 中后面的数据。
对于发送方,如果是有缓冲Channel ,那么不会阻塞。而如果是无缓冲Channel,当队列满了后,发送方会发生阻塞,只有队列里面被取出消息,腾出新的空间,发送方不再阻塞。
func main() {
ch := make(chan int,10)
go func (){
for num := 1 ;num <= 100; num ++ {
ch <- num //发送方发送10条数据后,队列就满了,这个表达式就会进入阻塞状态
println("send message to channel , value is ",num)
}
}()
time.Sleep(5 * time.Second)
frist := <-ch
println("receive message from channel once , value is ",frist)
second := <-ch
println("receive message from channel once , value is ",second)
time.Sleep(5 * time.Second) //当接收方接受到2条数据后,发送方才解除阻塞,继续发送2条数据,队列就有又满了
}
//send message to channel , value is 1
//send message to channel , value is 2
//send message to channel , value is 3
//send message to channel , value is 4
//send message to channel , value is 5
//send message to channel , value is 6
//send message to channel , value is 7
//send message to channel , value is 8
//send message to channel , value is 9
//send message to channel , value is 10
//receive message from channel once , value is 1
//receive message from channel once , value is 2
//send message to channel , value is 11
//send message to channel , value is 12
使用 Channel 解决共享内存问题
func main() {
ch := make(chan int)
sum :=0
go func (){
for num := 1 ;num <= 100; num ++ {
ch <- num
}
close(ch)
}()
for {
if num, ok := <-ch; ok { //当通道关闭,无数据读到,返回 false
sum += num
} else {
break
}
}
println(sum) //5050
time.Sleep(5 * time.Second)
}
在 java 三方协程库 Quasar 有 Actor 和 Channel 的轻量实现,可以去使用。

